
我们都知道网络上的爬虫非常多,有对网站收录有益的,比如百度蜘蛛(Baiduspider),也有不但不遵守 robots 规则对服务器造成压力,还不能为网站带来流量的无用爬虫,比如最新补充:宜搜蜘蛛已被 UC 神马搜索收购!所以本文已去掉宜搜蜘蛛的禁封!相关文章)。最近张戈发现 nginx 日志中出现了好多宜搜等垃圾的抓取记录,于是整理收集了网络上各种禁止垃圾蜘蛛爬站的方法,在给自己网做设置的同时,也给各位站长提供参考。
修改网站目录下的.htaccess,添加如下代码即可(2 种代码任选):
找到如下类似位置,根据以下代码 新增 / 修改,然后重启 Apache 即可:
然后,在网站相关配置中的 location / { 之后插入如下代码:
将如下方法放到贴到网站入口文件 index.php 中的第一个 ?php 之后即可:
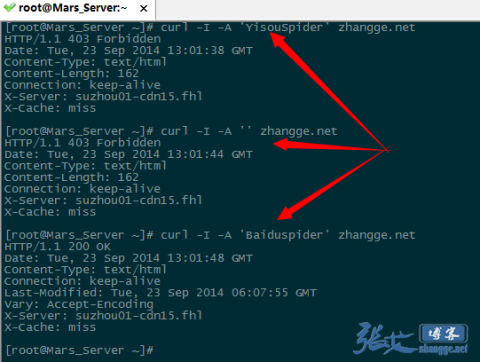
可以看出,宜搜蜘蛛和 UA 为空的返回是 403 禁止访问标识,而百度蜘蛛则成功返回 200,说明生效!
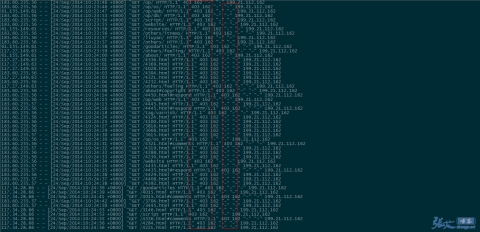
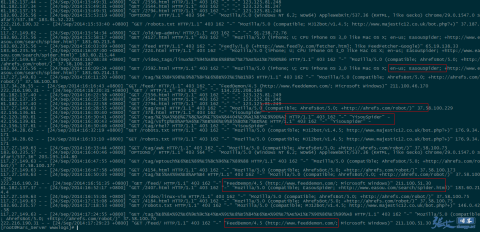
因此,对于垃圾蜘蛛的收集,我们可以通过分析网站的访问日志,找出一些没见过的的蜘蛛(spider)名称,经过查询无误之后,可以将其加入到前文代码的禁止列表当中,起到禁止抓取的作用。
我用的 DZ 3.1 也是被这些蜘蛛直接把服务费CPU100% LUIX系统 阿帕奇 如果要屏蔽是直接 在 通过修改 .htaccess文件 下面加上你上面的代码就行了吗?望回复 在线等 谢谢
修改以后 打开站点.htaccess里有错误,导致现在站点打开500错误。 之前遇到一搜的爬虫 疯狂
YisouSpider 还有uk 就发现这两个 疯狂的爬 一会服务器就瘫掉了 我看您用的是 WP博客程序 之前在网上也找了一些代码 加了好像没用 我用的DZ3.1直接把上面的修改 .htaccess文件加在最下面就行了吧不管他那些爬虫除了百度和360谷歌其余的都封掉烦都烦死了
另外,我在猎豹浏览器v5.2.9 提交评论的滑块是拉不动的,只能换到firefox下来提交了,你看看有没有什么问题。
最近重新折腾的时候才发现之前没有把配置写到https那个VirtualHost……折腾h2去了233
爬虫程序不可以自己设置UA吗? 比如设置为百度的爬虫UA 。如何反这种爬虫?
博主 请教一个问题 agent 识别为 curl/7.29.0 的是什么东西 是不是抓取工具啊?
哇 博主 真热心 这么快就回复了 那我问一下 这种按你说的那不是可以用作CC攻击?如果可以大GET量请求
你的VPS用的阿里云的ECS 的话 会不会被屏蔽页面啊 听说阿里云对这块拦截挺厉害的 什么 破解软件 注册机 VPN 这些东西很容易被屏蔽掉 那怎么办的?
我用第一种方法,把代码 加入 .htaccess 后,网站访问了不了,不知道是为什么?我的网站的zencart 系统
站长你好^^,很感谢你提供的恶意UA列表,想提一个意见看看能不能更新下呢?
2、jikeSpider盘古搜好歹也顶着个”中国搜索”的旗号,也该也不算恶意user agent吧?
其实这篇文字分享的是一种方法,各位站长想增加想删除都可以自己定义。所以这些我就不加上去了,比如Alexa Tool 这个Alexa排名的工具条
发现问题了f 不能放vhost里面 ,必须在上一层conf 下面,然后再include 就可以了。
发现有BUG,在nginx上设置之后,百度站长平台检测robots.txt会提示:无法访问您网站的robots.txt文件
百度暂时无法访问您服务器上的robots.txt买球官方网站文件,请检查服务器的设置,确保该文件能被正常访问。错误码:403
我设置过滤了ua为空的user_agent,用curl测试也成功了,但是为什么日志里返回的还都是200呢?求解
你往index.php里调用wp_die()是逗我玩么?wp环境还没建立呢你就调用那不报错?
发现有BUG,在nginx上设置之后,百度站长平台检测robots.txt会提示:无法访问您网站的robots.txt文件
百度暂时无法访问您服务器上的robots.txt文件,请检查服务器的设置,确保该文件能被正常访问。错误码:403
http301跳转https后,抓取http时会提示返回的301,抓去https提示403,这样是否工作正常呢?
为啥.htacess的我一用就是500错误,只能使用PHP的,不知道有没有效!
谢谢,现在原理我明白了,他只是屏掉,让他跳转 die(请勿采集本站,因为采集的站长木有小JJ!);
我可以说我的根目录/usr/local/nginx夏敏只有logs文件夹,根本没有conf,用的是1.1.4版本,后来换成了tengine2.2还是没找到小编说的文件,这怎么回事啊,另外试了apache的3中方法,都不行,500错误。
我是新手不太懂,只能搞懂第三种方法,是把内容复制进wordpress博客根目录下的index文件吗?

